Вайб-стратегия, или 3-я степень карго-культа #
Проблема #
Иногда разработчик берёт на себя ответственность за изменения уровня команды или компании:
- новый процесс разработки
- новый стандарт или регламент
- изменение подхода к чему-либо
- внедрение нового инструмента или технологии
Раньше, чтобы спроектировать такие изменения, люди делали скучные (и важные) вещи:
- читали книги и статьи
- перенимали чужой опыт на конференциях и за счёт нетворкинга
- экспериментировали и много думали
Времена меняются и ИИ активно внедряется в разработку. Некоторые люди увидели в этом отличный шанс делать так:
- спросить ИИ в чате
- скопировать ответ ИИ и «продать» его своей команде/компании
Это — третья степень карго-культа. Наверное, её можно назвать вайб-стратегией. И это неправильный подход.
Цикл копирования лидеров #
Цикл копирования процессов можно представить так:
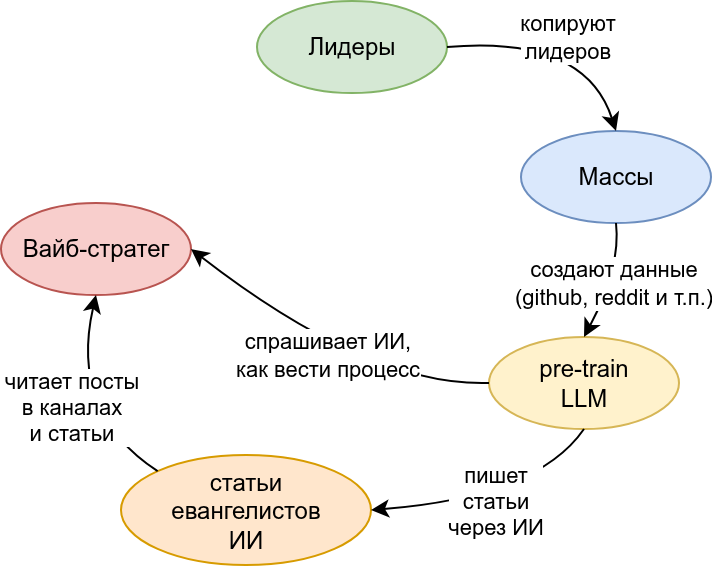
Объясним подробнее:
- Лидеры придумывают идеи самостоятельно — поэтому они и лидеры
- Массы стараются копировать у лидеров — путём повторения (эмуляции) или reverse-engineering процессов и идей
- Массы становятся основным источником данных для дата-сетов, на которых тренируются LLM (или Foundation Models) на этапе pre-train
- На запросы из разряда «как внедрить ИИ в команду системной аналитики» LLM отвечает на основе наиболее частых данных своего pre-train
- Евангелисты ИИ конечно же используют ИИ для написания своих постов, при этом часто цитируют авторитетные источники (блоги OpenAI или Anthropic) без понимания сути того, что сказано в первоисточнике
Любой, кто выстраивает стратегию на основе ответов LLM или советов евангелистов ИИ, выглядит как вайб-стратег, или сторонник карго-культа в 3-й / 4-й степенях.
А как правильно?
Старые советы работают #
Старые советы ещё действуют:
- читать книги, в которых изложена база
- по теме внедрения AI — книга «AI Engineering» / Chip Huyen
- читать внимательно блоги лидеров, оценивая сказанное с позиции критического мышления
- не стоит на 100% верить заявлениям про ИИ от лица компании, зарабатывающей деньги на API к LLM
- перенимать чужой опыт на конференциях и за счёт нетворкинга
- можно искать толковые Telegram-каналы и регулярно фильтровать тех, кто пытается набрать просмотров на хайпе, репостах или AI-генерации статей
- экспериментировать и много думать
- не забывайте фиксировать результаты экспериментов
- лучше всего это делать в формате Design Docs, доступных всем внутри компании
Учтите, что ИИ-модель отвечает на основе своего pre-train #
Можно применять критическое мышление, зная о структуре ИИ-моделей. По состоянию на март 2026, под ИИ обычно понимают transformer, или, точнее, GPT. Раскроем аббревиатуру GPT детально:
| Слово | Смысл |
|---|---|
| Generative | Модель генерирует токены (кусочки слов) один за другим, добавляя их в конец |
| Pre-trained | Модель использует знания из своего pre-train: она буквально проглотила «пол-Интернета» |
| Transformer | Модель использует механизм внимания, исходная суть которого — в попарном связывании смыслов токенов (кусочков слов) в пределах всего входного текста |
Знание о структуре позволяет прогнозировать поведение модели.
Представим себе такой сценарий:
- вы задали вопрос: «насколько ИИ повышает продуктивность разработчика?»
- в марте 2026 ответ будет в районе 20-30%
- причина в том, что ИИ-модель достаёт ответ из своего из pre-train, а в 2024-2025 годах самым популярным ответом были как раз 20-30%, вот модель и даёт этот ответ
- допустим, теперь вы спросите модель: «откуда ты взяла эти цифры?»
- в марте 2026 топовая ИИ-модель признает, что 20-30% высосаны из пальца, а дальше изложит соображения по влиянию ИИ на продуктивность разработки, ссылаясь при этом на популярные ретроспективные исследования прошлого года
- это даёт вам отставание на те же самые 1-2 года
Как бы вы не меняли свой вопрос, данные будут извлекаться:
- либо из pre-train модели, где доминируют устаревшие данные
- либо из результатов поиска путём из поверхностного осмысления ИИ-моделью
У модели нет реального опыта, проверенного лично. Нет идей, изобретённых самостоятельно. Всё, что сказано моделью, по сути не имеет отношения к реальному опыту.
Воспринимайте ответ ИИ-модели как отправную точку #
Мы можете задать ИИ-модели вопрос по стратегии, если вы вообще не разбираетесь в этой теме. Желательно использовать режим Deep Research.
После этого можно:
- Извлечь наиболее полезные источники и прочитать их самостоятельно (именно так, скучным и энергозатратным способом)
- Использовать ответ, чтобы понять свои «слепые зоны» (то, чего вы не видели на основании своего опыта)
- Извлечь упомянутые термины, подходы, техники и вникнуть в их суть
Скорее всего в Deep Research хорошей модели будет нечто полезное, особенно если исходный вопрос был задан со всеми нужными направлениями / ограничениями для модели.
Опирайтесь на реальный опыт других #
- Наверное, самое важное в анализе чужого практического опыта — отличать пустословов (которые скажут что угодно) от людей, которые говорят немного и по делу.
- Также важно отличать людей, которые видели лишь фасад строящегося здания, от тех, кто знает архитектуру «изнутри», потому сам её продумывал и строил, экспериментируя и отбрасывая нерабочие варианты
А кто такие лидеры? #
Чаще всего лидеры — это компании, которые самостоятельно придумывают и внедряют сильные идеи в свой рабочий процесс. Несколько примеров таких лидеров:
- Google и подход к тестированию, описанный в книге «Как тестируют в Google»
- статья Test Sizes появилась в декабре 2010, когда в индустрию ещё только входила идея трёхслойной Testing Automation Pyramid (модульные, интеграционные и сквозные тесты); по сути Test Sizes — это эквивалент деления Unit/Integration/E2E, но с более понятной эвристикой и плюсами/минусами каждого «размера теста»
- в той же книге описано, как Google с самого начала делал ставку на множество дешёвых серверов и на экономию на эффекте масштаба в разработке — задолго до того, как идея Platform Engineering стала популярной
- Microsoft и платформа .NET — async/await впервые появились именно в мире .NET; концепция stackless coroutines была проверена на языке F# и стала популярной после появления в языке C#
- Yandex и методология БЭМ (блок-элемент-модификатор)
К слову, с точки зрения эффективности разработчиков очень часто лидером оказывается Google: от них пришла концепция программной инженерии (книга «Software Engineering at Google»), DORA для измерения эффективности разработки и множество иных концепций, процессов, идей и технологий.